报告链接:http://www.oclc.org/us/en/reports/worldcatquality/214660usb_WorldCat_Quality.pdf
OCLC的Worldcat质量项目(Worldcat quality project)尤其关注重复记录管理的问题。2008年OCLC的报告(联机目录:读者和图书馆员想要什么,做个迟来的广告)对于Worldcat数据满意度的统计,在人们反映的问题中,重复数据和最少内容的记录(minimal record)是普遍存在的问题。
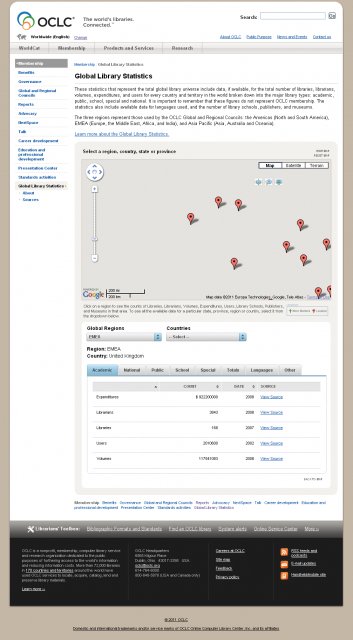
Worldcat数据库的快速增长加剧了数据质量的问题。问题首先是各国国家图书馆的导入数据,新的元数据超过了之前自动处理重复数据的工具的能力。但是这也让OCLC通过新进入数据库的多语种的数据,获得了进行多语种服务的机会(1998年,Worldcat数据库里的英文内容占64%;2010年,这个数字变成了43%)。其次是OCLC自2008年以来大量导入厂商数据(目前占书目数据库的1.59%),这一部分的数据内容比较少,而且会造成匹配、合并的问题。
OCLC从1991年就开始使用重复检测和分解(Duplicate Detection and Resolution, DDR)软件来处理重复记录。2010年9月,DDR对Worldcat数据库完成了一次完整的检测,删除了510万条重复记录。(从我个人的感觉来说,现在Worldcat的冗余数据确实比大概一年前要少了。)
2003年开始,OCLC开始允许“并列记录”(parallel records,即相同资源使用不同编目语种进行编目的记录。之前作为重复记录处理)。而重印的资源的记录,根据AACR2,要作为单独的记录来处理。但是对于终端用户来说,这种单独的展示是让人困惑的甚至于是失败的。
这还造成了另外的问题。OCLC号连接了元数据和资源的地点,也是Worldcat数据库和外部数据库的连接机制。(当我们从Worldcat数据库的资源页面导向外部的OPAC的时候,搜索项目就是OCLC号,这确实是很有用的一种标识符。突然想到本人很早之前翻译的一篇文章:OCLC控制号作为载体表现标识符)但是随着并列记录和重印(尤其是数字化的重印)的增加,元数据和馆藏信息越来越分散的分布在不同的记录下,这造成了多方面的问题,无论对于终端用户的选择困难还是图书馆之间的资源共享。
继而OCLC提出了一种新的通用标识符的概念:“全球图书馆载体表现标识符”(Global Library Manifestation Identifier, GLIMIR),这是OCLC自2009年开始的项目,用以解决上述问题。新的标识符希望能够克服编目语种、资源格式或者其他方面的问题,实现记录更好的聚合。这个项目目前即将实施,OCLC计划将在12财年度的上半年对Worldcat进行“GLIMIR化”的处理。正文第14页以下也展示了Worlcat在这方面正在进行的其他工作。对我而言比较重要的一个是去除无效的OPAC链接,以我的经验,目前这部分的体验已经足够的不好。
————————
对于没用过Connexion(以及新的Worldcat Local)的人来说,我一直很好奇Worldcat这么庞大的数据库在技术上的一些细节。在这个意义上我觉得这篇报告很有趣。这次看到GLIMIR感觉完全没有印象,Google了一下发现蛮多人都讨论了这个东西。